安装SciKit Learn 1 2 3 pip install numpy pip install sklearn pip install matplotlib
sklean中自带的数据
iris 鸢尾属植物数据(分类)
1 2 from sklearn import datasets iris = datasets.load_iris()
Boston房价信息(线性回归)
1 2 from sklearn import datasets boston = datasets.load_boston()
等等
分类器实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import train_test_split iris = datasets.load_iris() ## 加载数据 iris_X = iris.data ## X坐标,叶子长宽等属性 iris_Y = iris.target ## Y坐标, 植物品种[0, 1, 2] X_tain, X_test, Y_train, Y_test = train_test_split(iris_X, iris_Y, test_size=0.3) ## 将数据中的70%做为训练数据,30%作为测试数据 knn = KNeighborsClassifier() ## 使用Neighbors分类器模型 knn.fit(X_tain, Y_train) ## 使用数据中的70%对模型进行训练 print(knn.predict(X_test)) ## 对剩下的30%的属性进行预测品种 print(Y_test) ## 剩下的30%属性对应的真实品种值 print(knn.score(X_test, Y_test)) ## 对该模型中的30%预测结果与真实结果比较,对模型准确度打分
以上对该分类器实例得到的准确度达到93%以上
线性回归实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from sklearn import datasets from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from matplotlib import pyplot as plt boston = datasets.load_boston() ## 加载波士顿房价信息 boston_X = boston.data ## X坐标,房价相关属性:大小,位置等 boston_Y = boston.target ## 房价 X_train, X_test, Y_train, Y_test = train_test_split(boston_X, boston_Y, test_size=0.3) ##将数据中的70%作为训练数据,30%作为测试数据 model = LinearRegression() ## 使用LinearRegression线性回归模型 model.fit(X_train, Y_train) ## 对模型进行训练 Y_pre = model.predict(X_test) ## 对30%的测试数据进行预测 # plt.scatter(X_test[:,0], Y_test) ## 在图上展示与第一个属性相关图表 # plt.scatter(X_test[:,0], Y_pre) # plt.show() # y = model.coef_ * X + model.intercept_ print(model.coef_) ## 得到对于每个属性的斜率 print(model.intercept_) ## 得到在Y坐标的截距 print(model.score(X_test, Y_test)) ## 对该模型中的30%预测结果与真实结果比较,对模型准确度打分
以上对房价预测得到的准确度只有60%左右
Normalization(Scale) 如果X自变量的范围很大,会影响到数据的预测精确度,可以先对X坐标进行压缩,再对数据进行训练预测
1 2 3 4 5 6 7 8 9 10 11 12 13 from sklearn import preprocessing import numpy as np data = np.array([[10, 23, 3], [-100, 5, 2], [150, 23, 4]], dtype=np.float64) print(data) print(preprocessing.scale(data)) ## 执行结果 [[ 10. 23. 3.] [-100. 5. 2.] [ 150. 23. 4.]] [[-0.09774528 0.70710678 0. ] [-1.17294338 -1.41421356 -1.22474487] [ 1.27068866 0.70710678 1.22474487]]
更适合机器学习进行处理
Cross Validation 交叉验证 对一个模型打分,之前使用score方法进行评分,但是它只能对于一部分数据作为测试数据进行比较。使用cross_val_score的方法,会将数据分成多组训练数据与测试数据,最后取平均值的方式,对模型打分更准确。
1 2 3 4 5 6 7 8 9 from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import cross_val_score iris = datasets.load_iris() ## 加载数据 iris_X = iris.data ## X坐标,叶子长宽等属性 iris_Y = iris.target ## Y坐标, 植物品种[0, 1, 2] knn= KNeighborsClassifier() ## 使用KNeighborsClassifier分类模型 scores = cross_val_score(knn, iris_X, iris_Y, cv=5, scoring='accuracy') ## 将数据分为5份,其中4份为训练数据,1份为测试数据 print(scores.mean())
这样得到的评分会更准确。
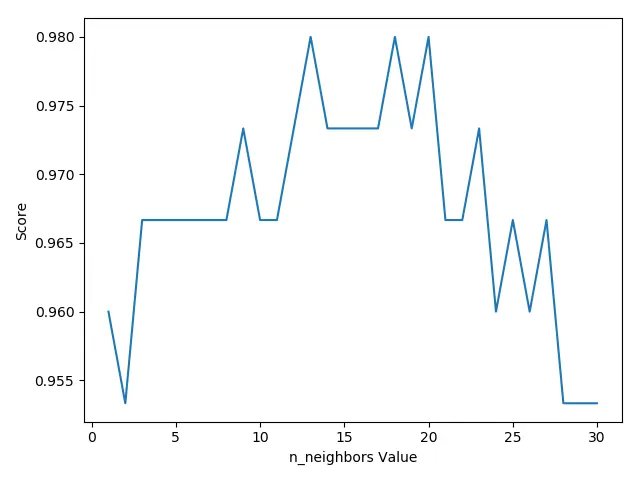
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import cross_val_score from matplotlib import pyplot as plt iris = datasets.load_iris() ## 加载数据 iris_X = iris.data ## X坐标,叶子长宽等属性 iris_Y = iris.target ## Y坐标, 植物品种[0, 1, 2] k_range = range(1, 31) max_score = [] for k in k_range: knn= KNeighborsClassifier(n_neighbors=k) ## 使用KNeighborsClassifier分类模型 scores = cross_val_score(knn, iris_X, iris_Y, cv=10) ## 进行交叉验证打分 这个值(准确度)是越大,越准确 max_score.append(scores.mean()) ## 计算交叉验证打分的平均值 ## 将数据在图中打印出来,显目地看到不同n_neighbors值对结果的影响 plt.plot(k_range, max_score) plt.xlabel(u'n_neighbors Value') plt.ylabel(u'Score') plt.show()
从图中可以我们选择k值,选择12到18之前的值,会有更准确的预测。
过度学习(随着训练数据越多,准确度越低)
learning_curve参数固定时,随着训练数据增多,查看准确度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import numpy as np from sklearn.model_selection import learning_curve from sklearn.datasets import load_digits from sklearn.svm import SVC from matplotlib import pyplot as plt digits = load_digits() ## 导入数据 X = digits.data ## 数据X坐标值 Y = digits.target ##数据Y坐标值 train_sizes, train_loss, test_loss = learning_curve(SVC(gamma=0.001), X, Y, cv=10, train_sizes=[0.1, 0.25, 0.5, 0.75, 1]) ## 对SVC(gamma=0.001)进行训练,并标记下10%, 25%, 50%, 75%, 100%作为训练集时的精确度 train_loss_mean = np.mean(train_loss, axis=1) ## 训练集准确度 test_loss_mean = np.mean(test_loss, axis=1) ## 测试集准确度 ## 将训练准确度与测试准确度画出来,看到模型不断训练,准确度不断提升 plt.plot(train_sizes, train_loss_mean, 'o-', color="r", label="Training") plt.plot(train_sizes, test_loss_mean, 'o-', color="g", label="Cross-validation") plt.show()
validation_curve 遍历可能的参数值,找到最合适的参数值
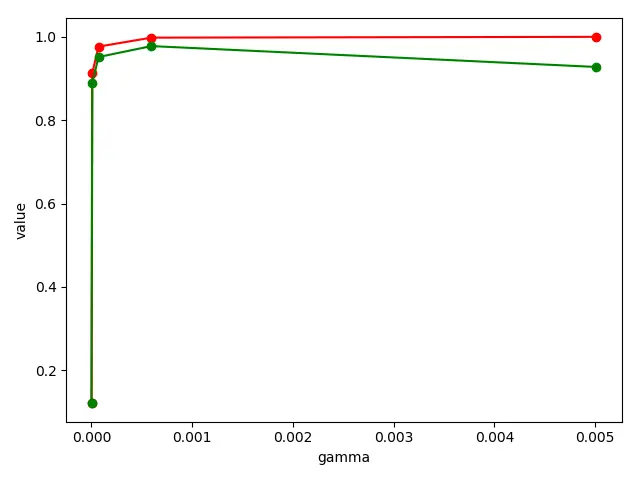
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import numpy as np from sklearn.model_selection import learning_curve, validation_curve from sklearn.datasets import load_digits from sklearn.svm import SVC from matplotlib import pyplot as plt digits = load_digits() X = digits.data Y = digits.target param_range = np.logspace(-6, -2.3, 5) train_loss, test_loss = validation_curve(SVC(), X, Y, param_name='gamma', param_range=param_range, cv=10) ## train_sizes为10%, 25%等记录一下 train_loss_mean = np.mean(train_loss, axis=1) test_loss_mean = np.mean(test_loss, axis=1) plt.plot(param_range, train_loss_mean, 'o-', color="r", label="Training") plt.plot(param_range, test_loss_mean, 'o-', color="g", label="Cross-validation") plt.xlabel("gamma") plt.ylabel("value") plt.show()
从图中可以看到,gamma使用0.0005值左右的数据准确度会更适合,也不会出现过度训练的问题。
保存训练后的模型
使用pickle模块保存对象
将模型保存到save/clf.pickle文件中
1 2 3 4 5 6 7 8 9 10 11 from sklearn import svm from sklearn import datasets clf = svm.SVC() iris = datasets.load_iris() X, Y = iris.data, iris.target clf.fit(X, Y) ## 训练模型 import pickle with open('save/clf.pickle', 'wb') as clf_file: pickle.dump(clf, clf_file) ## 将模型保存到save/clf.pickle文件中
将模型从save/clf.pickle文件中导入,并进行预测
1 2 3 4 5 6 7 8 from sklearn import svm from sklearn import datasets iris = datasets.load_iris() X = iris.data with open('save/clf.pickle', 'rb') as clf_file: clf = pickle.load(clf_file) print(clf.predict(X[0:1]))
使用joblib
将模型保存到save/clf.pkl
1 2 3 4 5 6 7 8 9 10 11 from sklearn import svm from sklearn import datasets from sklearn.externals import joblib clf = svm.SVC() iris = datasets.load_iris() X, Y = iris.data, iris.target clf.fit(X, Y) ## 保存数据 joblib.dump(clf, 'save/clf.pkl')
将模型从save/clf.pkl文件中导入,并进行预测
1 2 3 4 5 6 7 8 9 10 from sklearn import svm from sklearn import datasets from sklearn.externals import joblib iris = datasets.load_iris() X = iris.data ## 导入对象 clf = joblib.load('save/clf.pkl') print(clf.predict(X[0:1])) ## 对数据进行预测
参考教程: